


MoE: Mixture of Experts
MoE: Mixture of Experts
El Leonardo Da Vinci de las arquitecturas LLM

Hoy vamos a hablar de uno de esos palabros de moda en lo que inteligencia artificial se refiere. Conviene saber qué es lo que nos están diciendo cuando nos hablan de los MoE.
Moe no sólo es el nombre del barman de Los Simpson, también son las siglas de Mixture of Experts, traducido como Mezcla de Expertos.

MoE saltó a la palestra en diciembre del año pasado con la aparición del modelo open source Mixtral de la empresa europea Mistral (francesa para más detalle). Este modelo no es el primero en usar la arquitectura MoE, pero sí el primero en hacerlo público.
A raíz de la publicación de Mixtral han ido apareciendo más modelos que están usando esta arquitectura, tales como Yi, Jamba, DeepSeek, FusionNet o Gemini (Google). La lista es enorme.
Otro punto que ha hecho relevante al modelo es el rumor en la comunidad de que también GPT4 (OpenAI) podría tener arquitectura MoE. Esto es algo que no sabemos con certeza a causa de la poca información que proporciona OpenAI sobre sus modelos, pero es algo que podría haberse filtrado, y explicaría, además, el aumento de velocidad y rendimiento de GPT4 respecto a anteriores versiones del modelo.
¿En qué consisten los MoE?
La idea es bastante simple y no es nueva (parece que nació en un artículo de 1991). En los LLM’s que conocíamos hasta ahora existía un único modelo que era quien trataba de resolver la consulta que enviábamos por prompt.
En los MoE esto ya no es así, la arquitectura MoE está compuesta por un modelo que hace de distribuidor o enrutador (también conocido como Gating Network o Router) y un conjunto de modelos especializados (cada uno bueno en un tipo de tarea).
El modelo distribuidor envía la consulta que le enviamos a los modelos especializados, pero, y aquí está lo importante, debe decidir qué peso le concede a cada modelo. El resultado o respuesta a la consulta que le realizamos será pues una suma ponderada de la respuesta generada por los modelos especializados. Por ejemplo, si enviamos al modelo la consulta “¿Cuánto son 2 + 2?”, el enrutador le dará más peso al modelo especializado en operaciones matemáticas y mucho menos peso al resto.
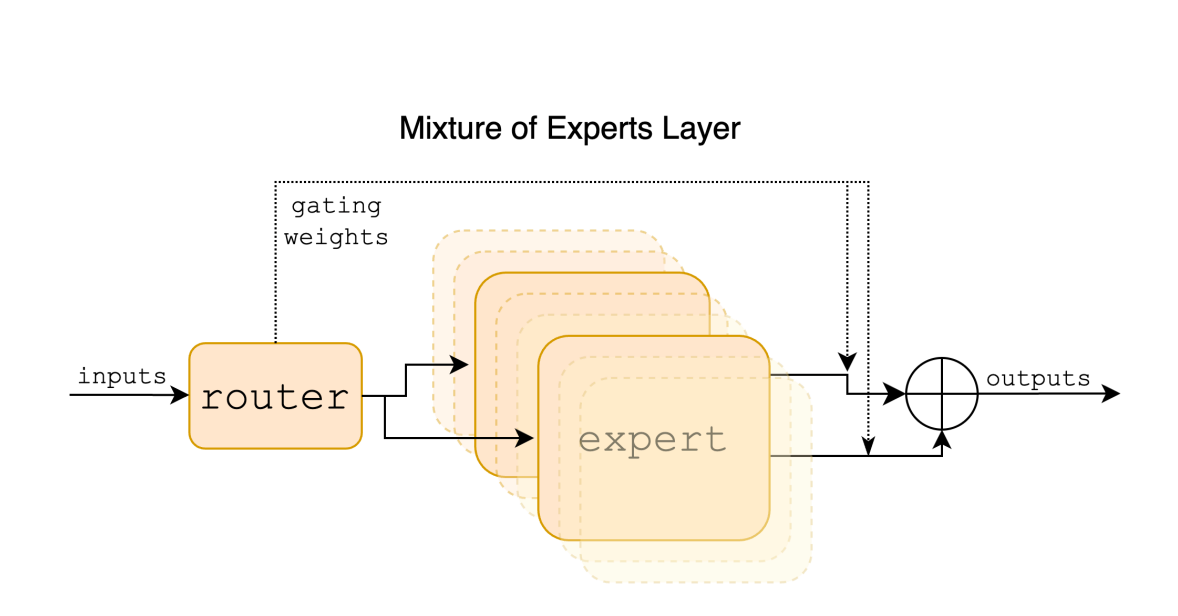
Si bien hay muchos modelos que están usando esta arquitectura, no todos usan el mismo número de modelos especializados ni los especializan en los mismos campos. Mixtral y GPT4 parecen tener un enrutador y 8 modelos especializados, pero, sin embargo, los modelos de GPT4 son mucho más grandes que los de Mixtral.
La gran ventaja de la arquitectura MoE es bastante evidente. El hecho de usar modelos más pequeños hace que sean más rápidos. Así, un modelo LLM que use la arquitectura MoE se calcula que va hasta 6 veces más rápido (para un LLM con 8 modelos) que uno equivalente sin arquitectura MoE. La rapidez y la eficiencia no solo se atribuye al tamaño sino también a la independencia, al ser modelos independientes pueden correr en máquinas diferentes.
Al tener modelos especializados, también es más eficiente al procesar consultas que manejen datos complejos. En este caso el enrutador deriva la información más adecuada para cada modelo, derivando los datos más convenientes según cada modelo.
Digamos que la lógica de la mejora de esta arquitectura es que si no eres capaz de mejorar el modelo haciéndolo más grande (al parecer el aumento de parámetros hace decrecer la eficiencia del modelo por los mayores requerimientos de computación) intenta usar varios modelos más pequeños al mismo tiempo.
Podemos ver que MoE es una optimización del funcionamiento de los LLM’s. Esto provocará una mejora de rendimiento en general. Veremos modelos que antes necesitaban una GPU potente y que ahora serán capaces de funcionar dentro de un smartphone (ya hay modelos mini específicamente pensados para eso).
Mi duda es si hemos llegado al tope, si ya dependemos exclusivamente de las mejoras de hardware, o si aún hay alguna tecnología novedosa que nos permita hacer otro salto de rendimiento. Veremos.
Un pequeño paréntesis para los más veteranos antes de terminar.
El nombre MoE nos puede hacer recordar otro concepto relacionado con la inteligencia artificial, los sistemas expertos. Los primeros sistemas expertos datan de la década de los 70 y podrían considerarse unos antepasados muy lejanos de los MoE. Se han venido usando ampliamente desde la aparición de las computadoras. Pero es preciso dejar claro que nada tienen que ver tecnológicamente hablando con los MoE, sólo comparten el apellido. Los sistemas expertos son más bien sistemas basados en reglas, es decir, “si pasa esto haz lo otro”.
Despedida y cierre
Esta semana vuelvo a enviar con retraso. Cosas de la vida. Hoy he vuelto a mirar un poco hacía la inteligencia artificial. Seguro que no será el último envío de este tipo que haré, es decir, de explicación de conceptos que se van oyendo en relación a la IA. Espero os haya gustado.
Respecto de tu duda de si hemos llegado al tope, estoy seguro que nos vamos a estar saltando esos topes continuamente a partir de ahora, la cuestión es cuando llegará una tecnología realmente disruptiva y nos haga saltar adelante como lo ha hecho en 2023 la IA generativa puesta a disposición de todo el mundo.